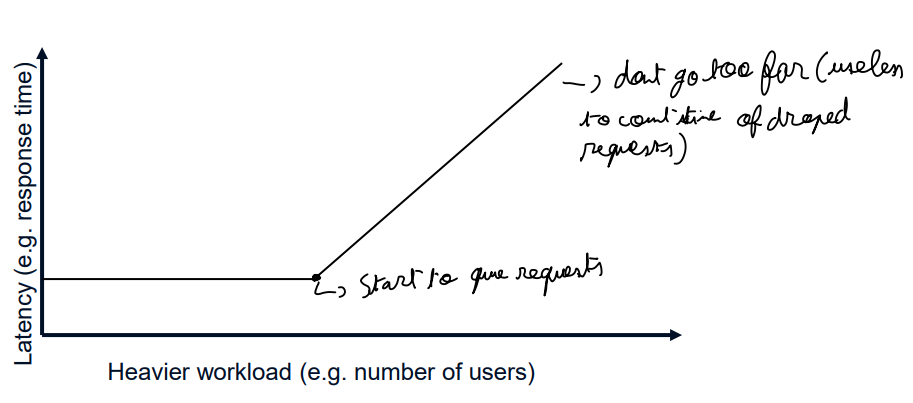
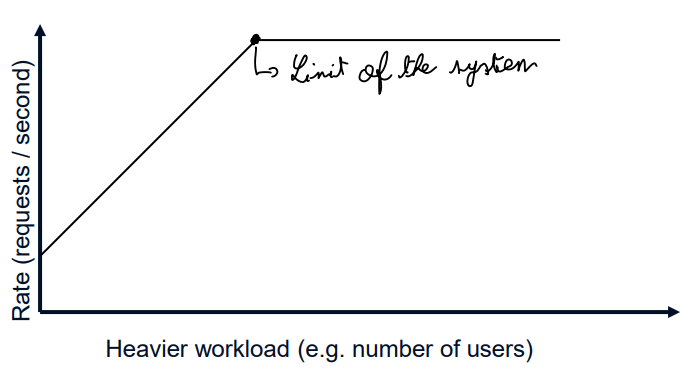
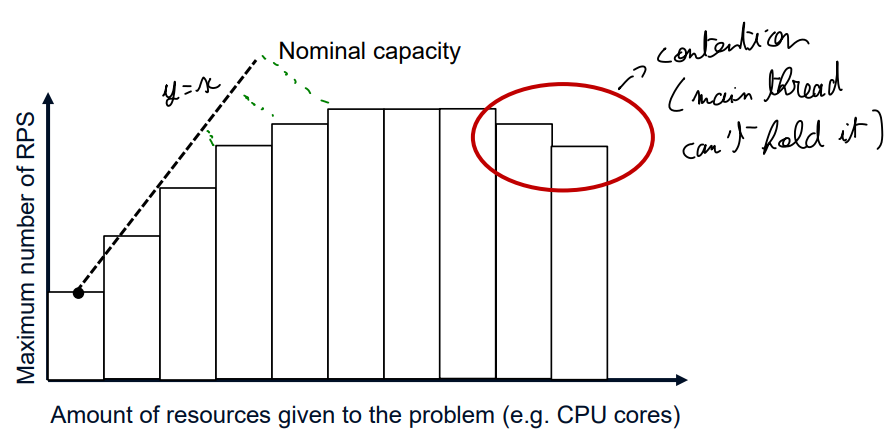
There exist 3 types of performance evaluation
The following metrics are the most used for performance evaluation.
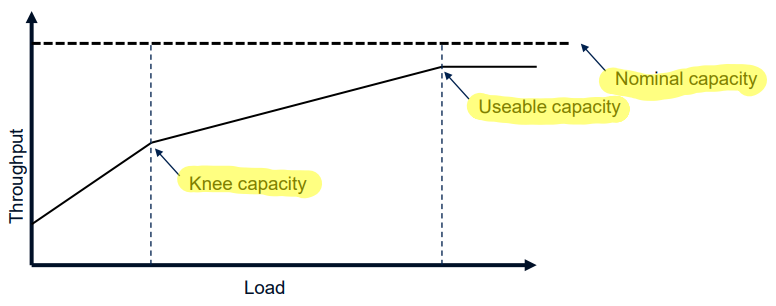
Note the difference between Throughput and Goodput, respectively corresponding to the data usage and the valid data usage
The knee capacity is the capacity beforce getting a lower gain.
The usable capacity is the capacity before reaching a plateau
The nominal capacity is the capacity in ideal conditions

The one-at-a-time model do not study at all the interaction.
The full factorial model is perfect in theory but take an exponential amount of time based on the number of variable.
The Fractional factorial designs select only certain parameters to study the interaction to reduce the time.
The idea is the study each k factor at two levels (often enable/disable)
The verification model is a model that is used to verify the results of a simulation or a measurement.
A test workload is any workload used in performance studies.
Test workloads and real workloads should have the same elpased time, resource demands and resource usage profile.
A workload should be considered at different loading level. Full capacity (best case), Beyond full capacity (worst case), raal observed load (typical case)
Main memory is volatile => no power = data loss.
Main memory is untyped. Everything is just bytes. A single int can be splitted to multiple addresses.
Each instruction have a specific Opcode followed by the different operand of the instruction.
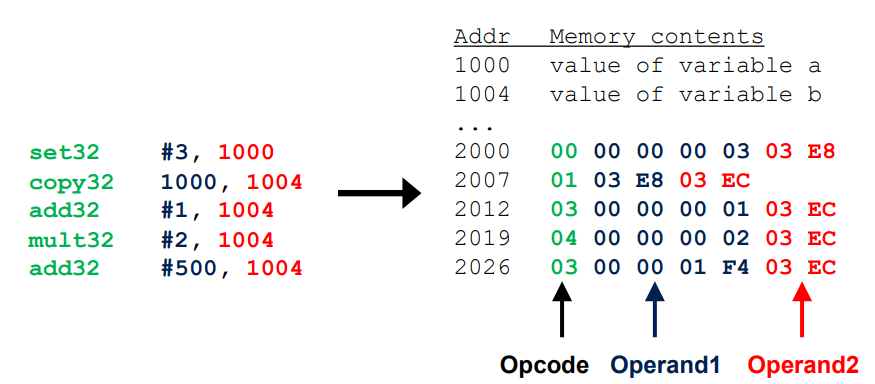
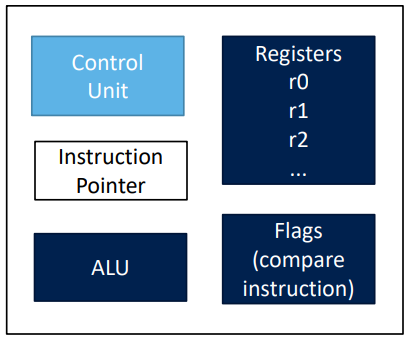
The control unit is doing the following steps sur execute a program :
The Jump instruction can modify the program counter to reach a certain instruction. It can use flags to do it only under certain conditions. For example the jumpIfGreater instruction checks the flags.
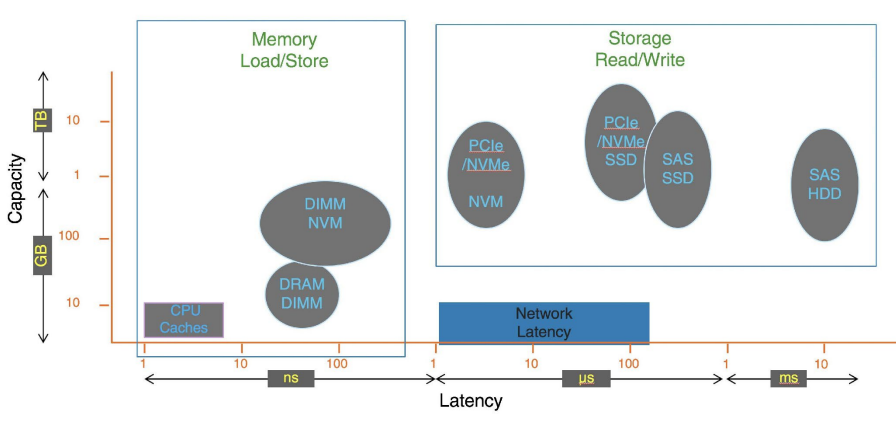
Reading to memory take around 100 nanoseconds which is a lot. We want to acces some memory realy fast. Thats the goal of registers.
CPUs also need indirect addressing to implement array accesses where the index is a variable. The asembly code looks like that.
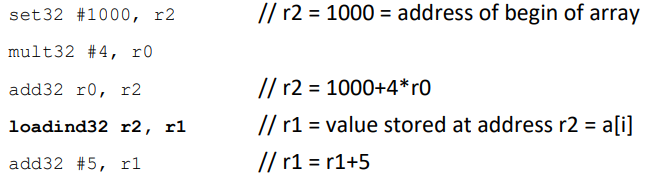
As arrays are used a lot in programing, most CPUs have a speciial instruction to access them : loadind32 [4*r0+r2], r1
ISA is one of the biggest difference between CPU architectures.
Intel tipicly use 2 operand (shorter, more powerfull and permissive) while ARM CPUs are using 3 operand instructions
Intel CPUs are using CISC (Complex Instruction Set Computer) while ARM CPUs are using RISC (Reduced Instruction Set Computer).
The cache is a memory component that stores data, so future accesses to that data can be executed with less costs. In CPU, cache is made of SRAM while the maine memory is made of DRAM.
Locality is the fact that a program is accessing the same data multiple times. There are two types of locality :
The hit rate is the percentage of data that is found in the cache.
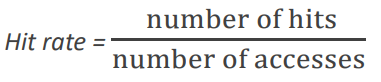
Following the same principle we can define the miss rate as 1 - hit rate.
The OPTIMAL management algorithm is the idea that a requested object will always be in the cache. It is impossible as we need to know the future to do that.
The FIFO management algorithm is the idea that the first object in the cache will be the first to be removed. It is not optimal as the first object may be the one that will be used the most.
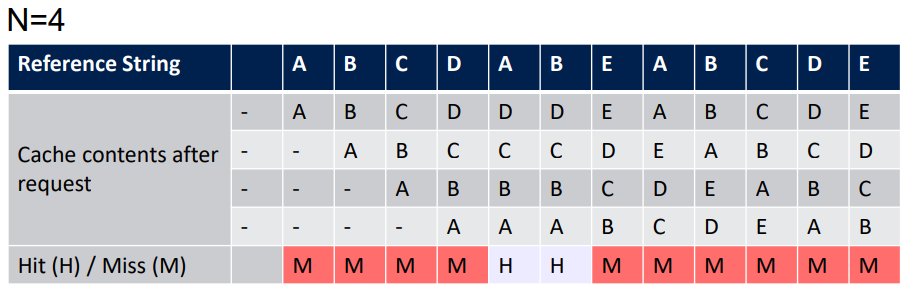
The FIFO suffers from Bélady's anomaly: a bigger cache does not always give a better hit rate. In the previous example, a cache of size N+3 instead of N=4 would have given better result.
The LRU (Least Recently Used) management algorithm bring new requested object to the cache. If the cache is full, remove the object that was not requested for the longest time.
The LRU can be implemented as a simple sorted list where we update a reference to the front of the list if it is requested such that the end of the list will always be the least recently used object.
the OPTIMAL and LRU are called stack algorithms. This means that the hit rate will always improve with the increasing size of the cache.
The LFU (Least Frequently Used) management algorithm is almost the same than LRU but take the frequency into account. To do so we need to keep a table with the occurences of each element of the cache.
This algorithm use an aging function that reduce the frequency over time. At some time the execusion of this function could look like this : 𝑓𝑖 ≔ max(𝑓𝑖/2 , 1) for all i. We choose to devide by two as it is a simple bit shift.
The concept is to not store each memory adress individualy in the cache but to store a line of memory starting at the address we are accessing.
With this technique we introduce the idea of tag instread of address. The adress could countain the tag corresponding to a cacheline, and some bits for the offset in the cache block.
Using these blocks improve the cache hit rate because of the space locality.
Comparisons of tags are done in parallel for all entries (good time complexity O(1) but high power dissipation! All comparators are active at the same time)
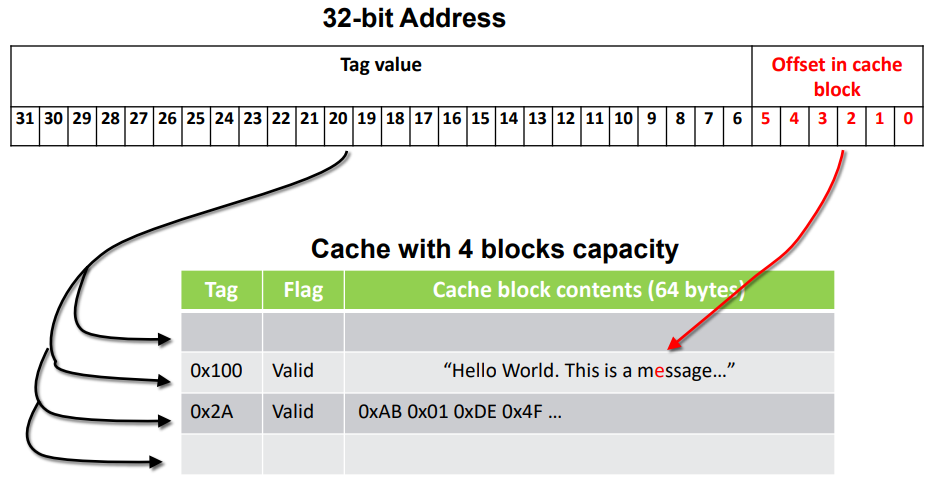
The problem of Full Associative Cache is that we have to compare a lot of addresses to know the position in the cache. We add the fix concept of row in this section to only need to use one comparator.

The principle of contention is that if the CPU try to access a two different adress placed in the same cache line, the second one will get a cache miss and the cache line will be replaced.
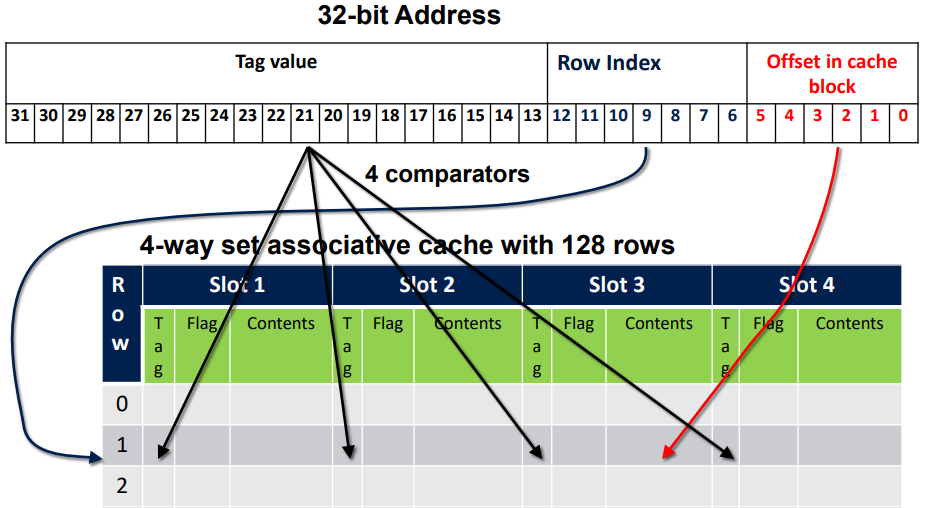
Almost the same that cache with direct mapping but here we have multiple slots for each cache line. When requesting an address, look for all the tags in the slots and compare them with your tag in your address to find a match.
A cache having 4 slots per line is called a 4-way set associative cache.
Cache is splitted into L1, L2 and L3 cache. lower is faster and smaller. Here are two ways of managing the cache :
| Cache type | Capacity | Latency |
|---|---|---|
| CPU register | 128 bytes | 0.2 ns |
| L1 cache | 32 KBytes | 1 ns |
| L2 cache | 256 KBytes | 5 ns |
| RAM | 8 GBytes | 100 ns |
| Local hard disk | 1 TBytes | 1-10 ms |
| Remote server | x TBytes | > 500 ms |
| Tape backup | X TBytes | > 5 minutes |
The write-back method is more complicated but more efficient.
It is long to wait for the the memory to write back data each time we have a dirty block. This is why we use a write buffer that quickly handle a lot of write operations and will execute them later when the memory is ready to.
The CPU can continue its execution without waiting the end of the write operation.
The idea of prefetching is to bring data into the cache before it is requested. This is done by the CPU when it detects a pattern in the memory access.
Here are some basic exemple of prefetcher :
Some code optimisation can be done to optimize the cache prefetching such as linear matrix multiplication, or data alignment (how to organize data based on how we will access it)
Each instruction done by the CPU take more than one cycle (read instruction, parse it, get content of variable, perform instruction, write result). This is why we use instruction prefetching to fetch multiple instructions at the same time.
Overlaps execution of instructions. while we decode an instruction we can start fetching the following one, ...
The first basic approach suffers from memory access problems and dependency between instructions.
A solution to these problems is instruction reordering. By changing the order of non-dependant instructions we can gain a lot of time.

Modern CPUs can reorder instructions themselves during runtime. This is called out-of-order execution
The branching is when the execution deviates from a straight line.
Branching happens when jumps are used (loops, conditions, ...)
Branching is bad for pipelining as the CPU have to restart the pipeline to the address of the new IP after each jump.
To gain some time, the CPU start the pipeline of the jump immediately after decoding the instruction.
Conditionnal jumps are even worse because we don't know the branch to choose. The same effect is created by indirect jumps (jump to a non fixed address stored in memory)
A first approch to reduce branching is to inline small functions. Don't do it for big ones as it is bad for cache.
Loop unrolling can reduce the number of compare and jump function. It will reduce branching and make the code faster.
Modern compiler already unroll loops for us. Small loops can even be completely unrolled removing all the jumps
Sometimes we don't know in advance the number of iterations. Strip mining is the concept of doing multiple versions of the loops to unroll until we can't
The concept is that the pipeline do not wait for the result of the comparison. It will continue the execution and abort and restart the pipeline if the result of the comparison was not good.
The speculative execution need a Branch prediction to work. If this prediction fail, it's called a branch-miss.
The speculation is directly done in hardware.
It is possible to speculate through multiple branches but is complicates the speculation recovery.
Speculation is only energy efficient for great perfomance improves.
Some CPU have unlikely jumps and likely jumps to help it choosing what branch to choose.
Some CPUs keep a table of the use of different jumps to help their branch prediction.
Some instruction such as compare and jumpIfGreater could be executed in only one instruction. But we dont want to add too many instructions (compatibility and opcode size).
The solution is superscalarity. Fetch two instruction at the same time, decode them at the same time and them check whether the instructions belong together. If it is the case, run it like a super-instruction. These kind of instructions only exists inside the CPU.
Sometimes a program use a same register for logically independent instructions. Renaming the register for the independant instructions allow to execute it in parallel.
The register renaming happens transparently during the runtime inside the pipeline.
The CPU turn instruction into many small instructions to allow them to be ordered, and executed in parallel.
Meltdown is a security breach that allow a program to read the memory of the kernel.
The idea is to use the speculative execution to read the memory of the kernel. The program will try to read the memory of the kernel and will be stopped (segfault but we can handle it). But the CPU will have already executed the instruction and will have put the result in the cache.
By puting the value we want to access in an array and by accessing the array with an index that is the value we want to access, we can see that the access time is faster when the value is in the cache.
Meltdown multiply the secret value by 4096 to prevent the prefetcher to get close data in the cache and make false positive.
The MMU (Memory Management Unit) is a hardware component that translate virtual address to physical address.
The idea is that softwares never interract directly with the physical memory. They only use virtual memory.
The MMU is an hardware componant integrated in the CPU.
The MMU keeps a table of the memory addresses to translate a part of the virtual address to a physical address.
Only the upper bits are decoded to a physical adress and the rest of the bits stay the same to indicate the position in the page (the same in physical and virtual).
For example in a 32 bits system, we can keep 12 bits for the pages offset. This leads to 4 KBytes pages.
Recent CPU uses other pages size such as 4KB, 2MB, 1GB.
To allow quick information, all valid entries in the page table have the Present (P) flag set.
Each process has its own page table. This allows to isolate the processes from each other.
This means that multiple program can have access to the same virtual memory adresses without linking to the same physical memory ones.
In some casis we still want to share the same data between two processes. This can be done safely by using the Read only (R/W) flag.
If a user need a lot of continuous places (For long arrays for example), the virtual memory can show the illusion of continuous storage while spreading it on the physical memory.
When a program try to access a memory address that is not in the page table, the MMU will raise a page fault exception. Here are the steps followed when a page fault occurs
This can be used for an automatic stack growth to allow to program to use space that they dont have to manualy reserve.
Here are all the reason to get a page fault :
Virtual memory allow to allocate more memory than this in physical memory in a computer by swapping out data to the disk, and switching their P flag to 0, allowing the page to be used by our process.
When we want to acces the swaped out page again, the OS can swap it in again.
We need some page replacement algorithm to decide wich page to swap in and out. We can use the A flag (access flag) that we set to 0 every U second to know which pages are not recently used.
Similar to dirty flag in cache. Set to 1 if the CPU writes to an adress inside a page.
This means that when we swap in a page from the disk, it does not delete the copy of the page on disk.
So if we have to remove the page again and that D = 0, the copy on the disk is still good so no need to write it on disk again.
Page tables are huge. and most of them are empty !
This is why we use Multi-level page tables. It uses Directory, table and offset to store the data more efficiently. This lead to a slow down of the MMU.
The TLB (Translation Lookaside Buffer) is a cache for the page table. It is a small cache that store the most used pages.
It is implemented as a Full Associative or Set Associative cache but for storing frame numbers and flags instead of data.
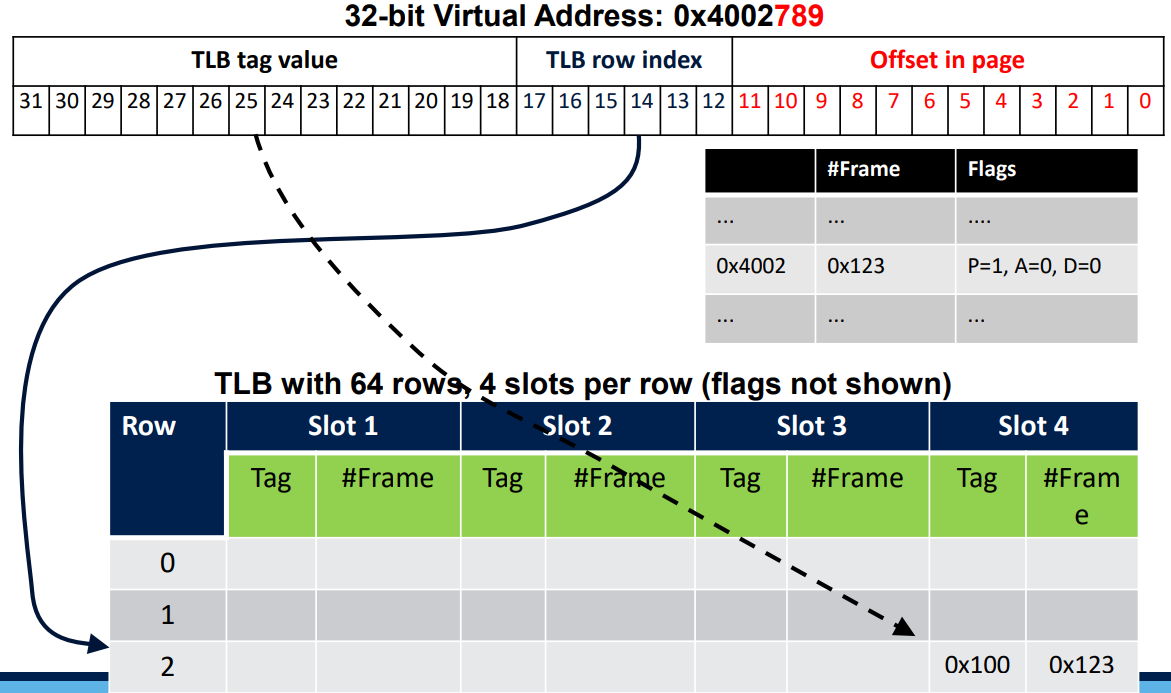
CPUs have now multiple TLBs per core.
TLB must be different for each process so we have to flush it all on context switches or uses an ID in the TLB for each process.
A CPU working with virtual addresses only need TLB in case of cache miss. The cache is not transparent and we need the help of the OS to clear the cache en try in case of changes in it. We also could have multiple virtual adresses pointing to the same physical block resulting in double cache of the same value.
A CPU working with physical adresses is transparent, slower (every acess need to uses TLB) and if we have a TLB miss we neek to wait even if the data is in the cache.
In practice CPU are doing a bit of both.
Users cannot modify the page table pointer. This is whu CPUs work in two modes
Privileged mode is NOT the same thing that sudo mode on linux !
CPUs use a U flag in the page tables that mark pages than can be read by users. A page with U=0 will lead to a pagefault.
One instruction is executed on one data at a time.
By using a single instruction, we can do an operation on multiple data
SIMD is an extention of the ISA. It allow to continue to think sequencially.
The idea is to use vectorized instructions to perform the instruction on a list of items. Intel AVX is a good example.
Multiple instructions are executed on multiple data at the same time.
MIMD = Multicore CPU
Each core can be SIMD
Each core can execute multiple threads at the same time.
Equivalent of HyperThreading from Intel
Works in hardware. Create two virtual CPUs in each core. Each pair of virtual CPUs uses the same L1 and L2 cache but uses different registers. They quickly switch to advance on both tracks. While one thread is waiting for memory, the second one runs.
Each core can execute multiple threads at the same time.
Building multithreaded apps is hard. We will always be limited by the sequencial part of the program.
Explained with Amdahl's low :

Using more CPU is not a solution as resolving one task will not be faster. This is the difference between strong and weak scaling.
CUDA will be an example of SIMT method
The GPU architecture is a lot about more smaller cores sharing the same cache and controler.
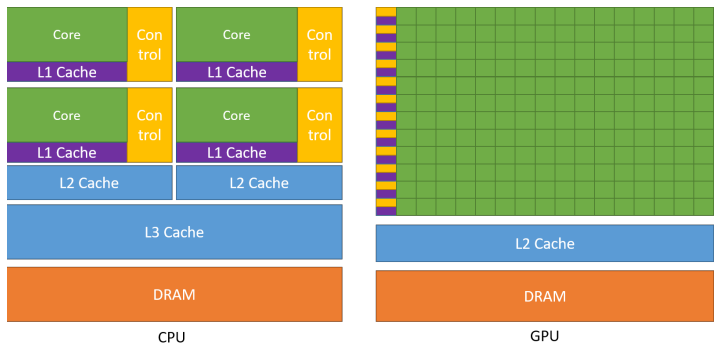
As seen before, GPU uses SIMT. A thread is associated with each data element (a column). Threads are organized into blocks (blocks of 32 threads to be run together). Blocks are organized in grid.
So we have blocks*threads*element
Each Streaming Multiprocessor will handle part of the blocks.
During the execution we will have n threads running on n ALU with N stacks but only one PC.
GPU are well optimized for those kind of executions.
PCI stands for Peripheral Component Interconnect. In the old days, a unique PCI bus was used to talk to all peripheral. Only one peripheral could talk at a time. The cache was outside the processor
Now some PCIe lanes are dedicated for the GPU. We now use group of lanes instead of a bus.
The speed of PCI have changed a lot with the version :
Current motherboards have multiple PCIe slots from different versions. We have to look for the best one to plug the GPU.
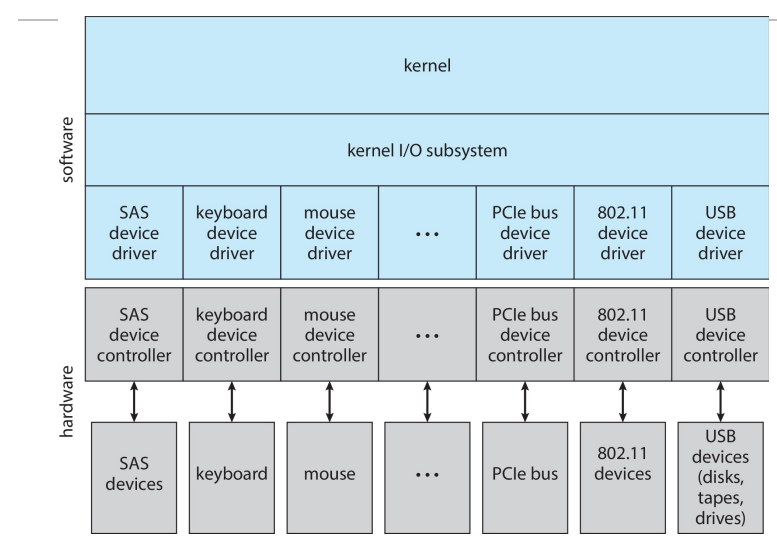
I/O are operated by a controller. Devices are controlled with I/O instructions. Devices have registers where device driver places commands, addresses, and data to write.
Devices have adresses used by PMIO (Port-mapped I/O instructions) or MMIO (Memory-mapped I/O). In MMIO, the device data and command registers are mapped to the processor adress space. This is used for graphics, high speed networking, ...
In opposite PMIO is extremely slow becausee it is synchronous, have dedicated instruction and have to copy byte per byte the data.
MMIO does NOT mean that accessing the address will go to the RAM ! It just mean that some physical memory space is mapped to the devices.
The BIOS (Basic Input Output System) is what enumerate devices and allocates space to them. Then the OS can re-map some large range for plug and play devices and large memory devices.
Polling is a way to access the bytes of a device that consist to wait for the device to be ready by looping on it :
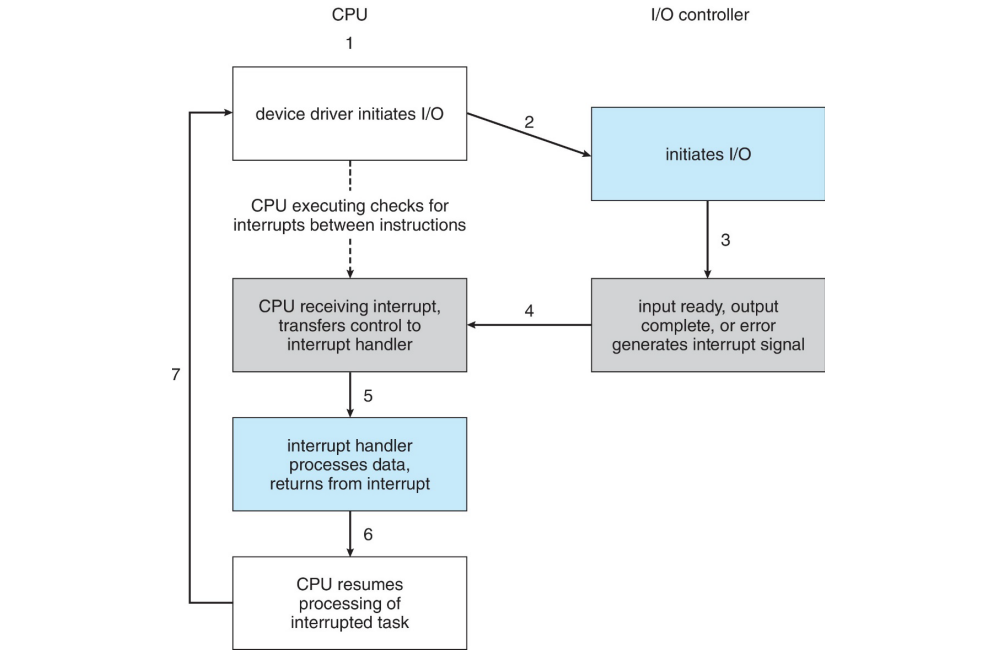
Interuption are the other way to access the bytes of a device. Polling was realy fast but not conviniant for slower devices.
Interruptions work using the CPU Interrupt-request line triggered by the I/O device and checked by the CPU after each instruction.
Some interrupt are maskable, grouped or delayed but finish all to the interrupt handler.
The Interrupt vector dispatch interrupt to the correct handler.
Interrupts are also used for exceptions such as SIGSEC, used for terminate a process, page fault, ...
Multiple thousands of interrupts are catched every seconds and most of them are shorter than 10 usecs.
MMIO is not magic! To copy huge amount of data, we need to mutch instructions. This is why we use DMA to avoid moving one byte at a time.
It requires a DMA controller. It bypasses the CPU to transfer directly data between I/O and memory.
To use it we have a DMA command block in memory through MMIO. We write source and destination adresses, read or write mode, and the count of bytes. DMA interrupt to signal the completion.
In reality the DMA is residing inside the CPU.
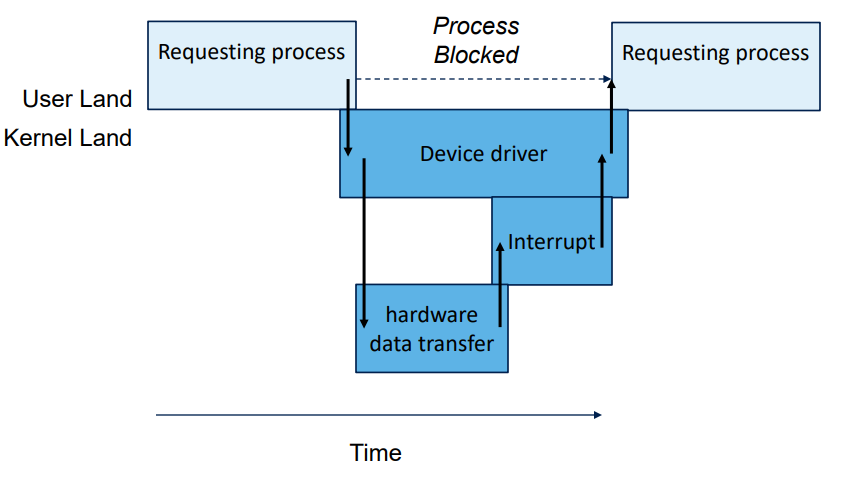
Process suspended until I/O completed
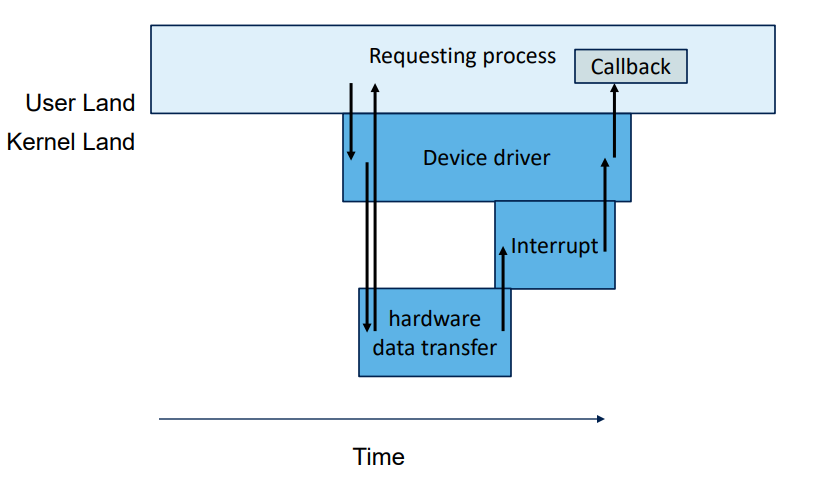
Process runs while I/O executes. DIfficult to use
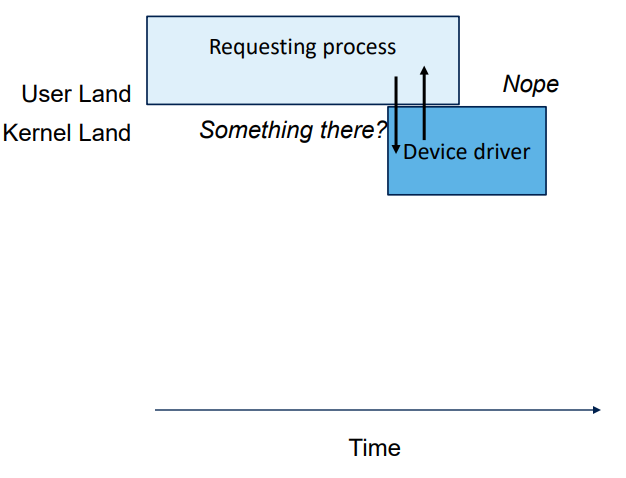
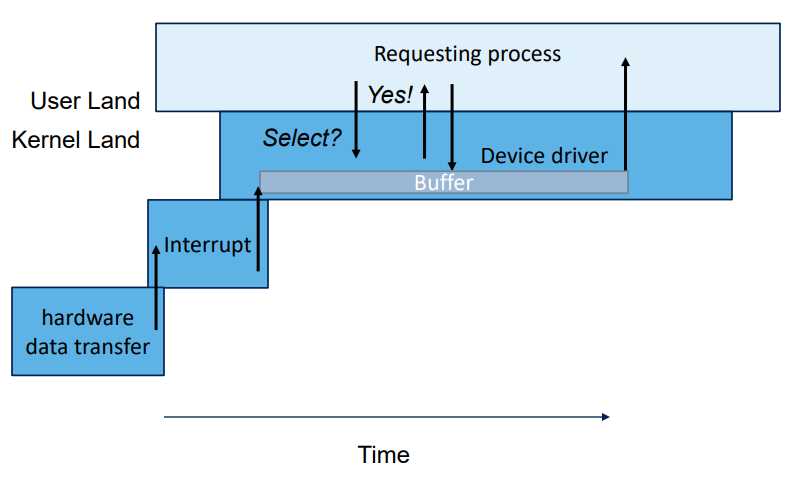
User interface, return quickly. Different if some data ready or not.
The user can requesto to write things to a device, the kernel will accumulate the data in a buffer before writing it to the device to cope with slow device for small transfers.
Allow to write or write multiple buffers at the same time.
"Scatter-gather" : More efficient than multiple calls to write or read. Decrease the number of system calls and context switches.
If the user write too much data in the buffer, the device will write an overwritten data. This is what can cause aliasing.
Double buffering can be use to have a kernel buffer and a device buffer.
Disks are slow ! A 15 000 RPM disk transfering 512B will take 4 ms of seek time + 2 ms of rotational latency + 0.2 ms of data transfer = 6.2 ms!
Some time can be gained if we re-order requests. The SCAN method serve all the request in the same track first and then serve the next track. When reach the inner or outer end of the disk, reverse direction. Cool but unfair.
Caching: faster device holding copy of data. Good for performance.
Spooling: hold output for a device.
We dont want user to breack our device. Most of instructions are privileged and can be called with system calls.
RDMA (Remote Direct Memory Access) is a way to access memory of a remote computer without using the CPU of the remote computer.
This is only done in datacenters
Queueing happens when multiple parties are waiting for access to a shared resource.
The service dicipline is the name given to the methodology of which client serve when. For exemple First come, first served (FCFS = FIFO).
Here are some metrics used in queueing theory :
We will not consider the /B/K/SD as we consither them to be 1 buffer, infinite population and FIFO service dicipline.
A is the arrival process, S the service time distribution and m the number of server
M will stand for poisson low (exponential arrival rate for example) and G for a general one.
This is all we had to know and then just apply following formula given at the exam.
